Image Classification(1)では、シンプルに行いましたが精度としては今の時代では全く話にならない結果となりました。
その理由としてRsizeやNormalizeをしていない事を指摘しました。最もとNormalizeは初期値でTrue=`実施`となっているようなのでNormalizeは影響しないかな(?)
そこで
1.前回にRsizeを加えて精度の変化を確認する。
2.DataBlock APIを使う。DataBlockを使うことで細やかなカスタム設定が出来るのでしょうが、勉強不足なので見様見真似で行ってみます。
▼Rsizeを加えたtraining
変更点は1つだけ
dls = ImageDataLoaders.from_folder(path, valid_pct=0.2, bs=16)
を
dls = ImageDataLoaders.from_folder(path, valid_pct=0.2, item_tfms=Resize(224), bs=16)
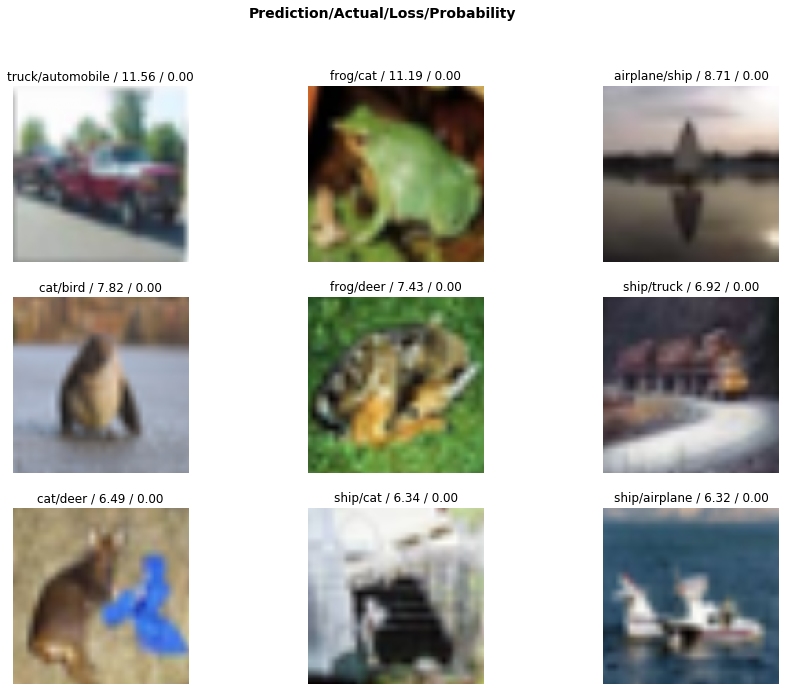
にするだけです。 その結果、精度は格段に良くなりました。
▼DataBlock APIを使ったtraining
おそらく、DataBlock APIを使ってのプログラミングで中級者、上級者への要望にも答えられるようになったのが今回のVer2の大きな変更点の1つだと思います。
ただ、fast.aiの「deep learningをごく一部の研究者ではなく、広くみんなが使えるように」の基本精神は変わることなく敷居の低いプラットフォームであってほしいと思います。
DataBlock APIを使った全プログラムを載せておきます。細かく説明できるほど理解していないので説明は改めてさせてください。
#fast.aiのインストール
! [ -e /content ] && pip install -Uqq fastai # upgrade fastai on colab
from fastai.vision.all import *
#データセットのダウンロードと解凍
path = untar_data(URLs.CIFAR)
#DataBlockAPIの設定
cifar10 = DataBlock(
blocks=(ImageBlock, CategoryBlock),
get_items=get_image_files,
splitter=RandomSplitter(valid_pct=0.2, seed=42),
batch_tfms=aug_transforms(),
get_y=parent_label,
item_tfms=RandomResizedCrop(224, min_scale=0.5))
#DataLoadeの作成
dls = cifar10.dataloaders(path)
#Learnerの作成
learn = cnn_learner(dls, resnet34, metrics=error_rate)
learn.fine_tune(5)
コアとなる部分はたったこれだけです。
そしてそのtrainingの結果は、1のResizeを行った場合と同じようなまずまずの結果が得られました。
これから少しづづfast.ai ver2も勉強していきたいと思います。