前回の続きです。今回は、プログラムを実装します。
とはいっても大したプログラムではありませんし、泥臭く同じことの繰り返しですがお許しください。
前回述べたCIFAR10、MNIST、など6種類のデータセットについて確認しますが、CIFAR10についての実施の様子を下記に記録します。
%reload_ext autoreload
%autoreload 2
%matplotlib inline
|
from fastai.vision import *
from fastai.metrics import error_rate
|
Data Preparation
path = untar_data(URLs.CIFAR); path
|
tfms = get_transforms(do_flip=False)
|
data=ImageDataBunch.from_folder(path,'train','test',ds_tfms=tfms, size=224,bs=16)
data.normalize(imagenet_stats)
|
データサンプルの表示
data.show_batch(rows=3,figsize=(5,5))
|
クラス名の表示
['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
クラスの数
10
クラス数は、
data.cでも求めることができます。
import torchvision.models as models
|
Learning rate finder
learn1 = cnn_learner(data, models.resnet34, metrics=accuracy, callback_fns=ShowGraph)
learn1.unfreeze()
learn1.lr_find()
learn1.recorder.plot()
learn1.recorder.plot_lr()
|
前回、fast.aiでのtraining手順として、
①learn.lr_finder()で学習率の目安を探索
②learn.recorder.plotで学習率をプロットし、最適な学習率を可視化する。
③learn.fit_one_cycle(●●,max_lr=○○)でtraining
④learn.unfreeze()でパラメーターの固定解除
⑤再度learn.lr_finder()で学習率の目安を探索
⑥learn.fit_one_cycle(●●,slice(◆◆,◇◇)でtraining
と書きましたが、ここでは③をとばしていきなり④のunfreeze()を行います。
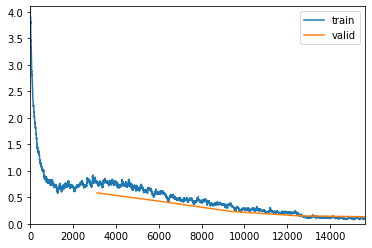
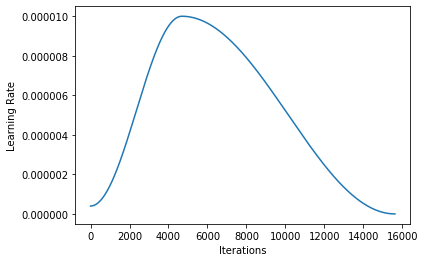
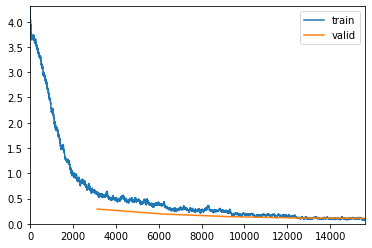
learn1.fit_one_cycle(5)
learn1 = cnn_learner(data, models.resnet34, metrics=accuracy, callback_fns=ShowGraph)
learn1.unfreeze()
learn1.fit_one_cycle(5)
learn1.recorder.plot_lr()
|
| epoch | train_loss | valid_loss | accuracy |
| 0 | 0.780216 | 0.583992 | 0.808 |
| 1 | 0.588731 | 0.414729 | 0.8604 |
| 2 | 0.352715 | 0.234025 | 0.925 |
| 3 | 0.203824 | 0.150889 | 0.9482 |
| 4 | 0.124859 | 0.132676 | 0.9565 |
学習率を指定しない場合の
学習率の初期値は3e-3のようです。
また、あとで調べるpct_startについては
0.30のようです。
learn1.fit_one_cycle(5,◆◆)を変化させて
●1e-1
learn1 = cnn_learner(data, models.resnet34, metrics=accuracy, callback_fns=ShowGraph)
learn1.unfreeze()
learn1.fit_one_cycle(5,1e-1)
learn1.recorder.plot_lr()
|
| epoch | train_loss | valid_loss | accuracy |
| 0 | 3.295467 | 4.346309 | 0.1173 |
| 1 | 3.921572 | 4.983587 | 0.1723 |
| 2 | 2.959883 | 6.040782 | 0.2201 |
| 3 | 1.76638 | 3.836934 | 0.4246 |
| 4 | 1.330334 | 1.197781 | 0.5942 |
●1e-2
learn1 = cnn_learner(data, models.resnet34, metrics=accuracy, callback_fns=ShowGraph)
learn1.unfreeze()
learn1.fit_one_cycle(5,1e-2)
learn1.recorder.plot_lr()
|
| epoch | train_loss | valid_loss | accuracy |
| 0 | 1.702964 | 1.565572 | 0.4127 |
| 1 | 1.388772 | 1.141736 | 0.6113 |
| 2 | 1.084691 | 0.952896 | 0.7039 |
| 3 | 0.814222 | 1.50364 | 0.7882 |
| 4 | 0.679151 | 0.866266 | 0.817 |
●1e-3
learn1 = cnn_learner(data, models.resnet34, metrics=accuracy, callback_fns=ShowGraph)
learn1.unfreeze()
learn1.fit_one_cycle(5,1e-3)
learn1.recorder.plot_lr()
|
| epoch | train_loss | valid_loss | accuracy |
| 0 | 1.043567 | 0.880254 | 0.7031 |
| 1 | 0.757948 | 0.619497 | 0.7985 |
| 2 | 0.508253 | 0.342101 | 0.8855 |
| 3 | 0.323111 | 0.230293 | 0.9217 |
| 4 | 0.22552 | 0.193924 | 0.9358 |
●1e-4
learn1 = cnn_learner(data, models.resnet34, metrics=accuracy, callback_fns=ShowGraph)
learn1.unfreeze()
learn1.fit_one_cycle(5,1e-4)
learn1.recorder.plot_lr()
|
| epoch | train_loss | valid_loss | accuracy |
| 0 | 0.637354 | 0.36355 | 0.886 |
| 1 | 0.424517 | 0.256843 | 0.9117 |
| 2 | 0.291843 | 0.180195 | 0.9392 |
| 3 | 0.133093 | 0.125177 | 0.9568 |
| 4 | 0.068266 | 0.108356 | 0.9646 |
●1e-5
learn1 = cnn_learner(data, models.resnet34, metrics=accuracy, callback_fns=ShowGraph)
learn1.unfreeze()
learn1.fit_one_cycle(5,1e-5)
learn1.recorder.plot_lr()
|
| epoch | train_loss | valid_loss | accuracy |
| 0 | 1.237 | 0.628205 | 0.793 |
| 1 | 0.56721 | 0.244785 | 0.9185 |
| 2 | 0.443136 | 0.186689 | 0.938 |
| 3 | 0.352476 | 0.163996 | 0.9453 |
| 4 | 0.360952 | 0.169788 | 0.9435 |
●1e-6
learn1 = cnn_learner(data, models.resnet34, metrics=accuracy, callback_fns=ShowGraph)
learn1.unfreeze()
learn1.fit_one_cycle(5,1e-6)
learn1.recorder.plot_lr()
|
| epoch | train_loss | valid_loss | accuracy |
| 0 | 3.051561 | 2.238222 | 0.2492 |
| 1 | 1.977203 | 1.172492 | 0.6117 |
| 2 | 1.501998 | 0.805571 | 0.7329 |
| 3 | 1.316191 | 0.725915 | 0.7575 |
| 4 | 1.308656 | 0.691376 | 0.7698 |
learn1.fit_one_cycle(5,◆◆,◇◇)を変化させて
●(1e-3,1e-2)
learn1 = cnn_learner(data, models.resnet34, metrics=accuracy, callback_fns=ShowGraph)
learn1.unfreeze()
learn1.fit_one_cycle(5,slice(1e-3,1e-2))
learn1.recorder.plot_lr()
|
| epoch | train_loss | valid_loss | accuracy |
| 0 | 1.223829 | 0.947184 | 0.6773 |
| 1 | 0.892643 | 0.820686 | 0.7632 |
| 2 | 0.635828 | 0.586226 | 0.8448 |
| 3 | 0.409529 | 0.38631 | 0.8978 |
| 4 | 0.282591 | 0.291427 | 0.9132 |
●(1e-4,1e-3)
learn1 = cnn_learner(data, models.resnet34, metrics=accuracy, callback_fns=ShowGraph)
learn1.unfreeze()
learn1.fit_one_cycle(5,slice(1e-4,1e-3))
learn1.recorder.plot_lr()
|
| epoch | train_loss | valid_loss | accuracy |
| 0 | 0.731875 | 0.467084 | 0.8481 |
| 1 | 0.491796 | 0.331305 | 0.8871 |
| 2 | 0.299885 | 0.207489 | 0.9278 |
| 3 | 0.158914 | 0.154469 | 0.9482 |
| 4 | 0.10062 | 0.131941 | 0.9585 |
●(1e-5,1e-4)
learn1 = cnn_learner(data, models.resnet34, metrics=accuracy, callback_fns=ShowGraph)
learn1.unfreeze()
learn1.fit_one_cycle(5,slice(1e-5,1e-4))
learn1.recorder.plot_lr()
|
| epoch | train_loss | valid_loss | accuracy |
| 0 | 0.603584 | 0.2928 | 0.9025 |
| 1 | 0.429166 | 0.191436 | 0.9351 |
| 2 | 0.212477 | 0.140253 | 0.9519 |
| 3 | 0.118028 | 0.115115 | 0.9613 |
| 4 | 0.103956 | 0.109139 | 0.9646 |
●(1e-6,1e-5)
learn1 = cnn_learner(data, models.resnet34, metrics=accuracy, callback_fns=ShowGraph)
learn1.unfreeze()
learn1.fit_one_cycle(5,slice(1e-6,1e-5))
learn1.recorder.plot_lr()
|
| epoch | train_loss | valid_loss | accuracy |
| 0 | 1.838387 | 1.090259 | 0.6381 |
| 1 | 0.851155 | 0.394355 | 0.8689 |
| 2 | 0.669168 | 0.306072 | 0.9017 |
| 3 | 0.521687 | 0.279249 | 0.9091 |
| 4 | 0.563496 | 0.270189 | 0.913 |
pct_startを変化させて
●pct_start=0.05
learn1 = cnn_learner(data, models.resnet34, metrics=accuracy, callback_fns=ShowGraph)
learn1.unfreeze()
learn1.fit_one_cycle(5, slice(1e-4,1e-3), pct_start=0.05)
learn1.recorder.plot_lr()
|
| epoch | train_loss | valid_loss | accuracy |
| 0 | 0.580275 | 0.482966 | 0.8361 |
| 1 | 0.391175 | 0.263471 | 0.9113 |
| 2 | 0.215597 | 0.192617 | 0.9355 |
| 3 | 0.140755 | 0.137328 | 0.957 |
| 4 | 0.089747 | 0.132845 | 0.9589 |
●pct_start=0.10
learn1 = cnn_learner(data, models.resnet34, metrics=accuracy, callback_fns=ShowGraph)
learn1.unfreeze()
learn1.fit_one_cycle(5, slice(1e-4,1e-3), pct_start=0.10)
learn1.recorder.plot_lr()
|
| epoch | train_loss | valid_loss | accuracy |
| 0 | 0.604141 | 0.427004 | 0.8577 |
| 1 | 0.37416 | 0.261463 | 0.9141 |
| 2 | 0.232374 | 0.16695 | 0.9448 |
| 3 | 0.143051 | 0.141318 | 0.9537 |
| 4 | 0.089341 | 0.132835 | 0.9567 |
●pct_start=0.30
learn1 = cnn_learner(data, models.resnet34, metrics=accuracy, callback_fns=ShowGraph)
learn1.unfreeze()
learn1.fit_one_cycle(5, slice(1e-4,1e-3), pct_start=0.30)
learn1.recorder.plot_lr()
|
| epoch | train_loss | valid_loss | accuracy |
| 0 | 0.750467 | 0.42111 | 0.852 |
| 1 | 0.498962 | 0.352008 | 0.8837 |
| 2 | 0.333238 | 0.2274 | 0.9265 |
| 3 | 0.158143 | 0.145393 | 0.9523 |
| 4 | 0.104481 | 0.131425 | 0.9571 |
 ● pct_start=0.50
● pct_start=0.50
learn1 = cnn_learner(data, models.resnet34, metrics=accuracy, callback_fns=ShowGraph)
learn1.unfreeze()
learn1.fit_one_cycle(5, slice(1e-4,1e-3), pct_start=0.50)
learn1.recorder.plot_lr()
|
| epoch | train_loss | valid_loss | accuracy |
| 0 | 0.659409 | 0.33861 | 0.89 |
| 1 | 0.576897 | 0.396411 | 0.8642 |
| 2 | 0.45204 | 0.295852 | 0.8992 |
| 3 | 0.213737 | 0.172917 | 0.9407 |
| 4 | 0.116044 | 0.141952 | 0.954 |
●pct_start=0.75
learn1 = cnn_learner(data, models.resnet34, metrics=accuracy, callback_fns=ShowGraph)
learn1.unfreeze()
learn1.fit_one_cycle(5, slice(1e-4,1e-3), pct_start=0.75)
learn1.recorder.plot_lr()
|
| epoch | train_loss | valid_loss | accuracy |
| 0 | 0.5036 | 0.260067 | 0.9109 |
| 1 | 0.533116 | 0.343204 | 0.891 |
| 2 | 0.541115 | 0.33661 | 0.8864 |
| 3 | 0.386734 | 0.247302 | 0.9149 |
| 4 | 0.180972 | 0.138309 | 0.9537 |
結果
上記にepoch、またそのグラフを示していますので大体の様子はお解りと思います。
これは、cifar10データセットの結果です。
その他のデータセット(imagenette2、MNIST・・・)の結果もまとめてグラフにしました。
まず、learn1.fit_one_cycle(5,◆◆)を変化させた場合、いずれのデータセットも学習率としては
1e-4乃至は1e-5が最適のようです。
また、MNISTは学習率に対して
ロバストネス(robustness)と言えるのでしょうか。
| 1.00E-01 | 1.00E-02 | 1.00E-03 | 1.00E-04 | 1.00E-05 | 1.00E-06 |
| imagenette2 | 0.266752 | 0.597707 | 0.914904 | 0.978599 | 0.984459 | 0.81707 |
| MNIST | 0.9948 | 0.9957 | 0.9971 | 0.9969 | 0.9951 | 0.9837 |
| dogs-cats | 0.507042 | 0.629108 | 0.826291 | 0.981221 | 0.948357 | 0.657277 |
| dogscats | 0.639 | 0.718 | 0.9685 | 0.986 | 0.9935 | 0.982 |
| cifar10 | 0.5942 | 0.817 | 0.9358 | 0.9646 | 0.9435 | 0.7698 |
| PET | 0.046008 | 0.114344 | 0.840325 | 0.924222 | 0.871448 | 0.121786 |
| insect | 0.204 | 0.2816 | 0.4816 | 0.8904 | 0.8568 | 0.3192 |
つぎに、learn1.fit_one_cycle(5,◆◆,◇◇)を変化させた場合、学習率としては
(1e-5,1e-4)が最適のようです。
| 1e-3,1e-2 | 1e-4,1e-3 | 1e-5,1e-4 | 1e-6,1e-5 |
| imagenette2 | 0.89656 | 0.966115 | 0.989299 | 0.974777 |
| MNIST | 0.9953 | 0.9966 | 0.9969 | 0.9941 |
| dogs-cats | 0.58216 | 0.981221 | 0.976526 | 0.920188 |
| dogscats | 0.9605 | 0.9865 | 0.9905 | 0.992 |
| cifar10 | 0.9132 | 0.9585 | 0.9646 | 0.913 |
| PET | 0.739513 | 0.912043 | 0.928958 | 0.702977 |
| insect | 0.392 | 0.868 | 0.9024 | 0.7376 |
さいごに、pct_startを変化させた場合、いづれのデータセットもあまり大きな変化は認められない結果となりました。
これが偶然なのかどうかは分かりません。pct_startを変化させるときの学習率(1e-4,1e-3)が適当な値だったため、pct_startの効果が現れにくかったのか、違う学習率だったらもっと差がでたのか不明です。
もっとも今回のような条件設定での実験のやり方は、あまり薦められるものではなく、詳しくは
実験計画法などを用いて検討をするべきでしょう。簡便にやりすぎたのかも知れません。
| 0.05 | 0.10 | 0.30 | 0.50 | 0.75 |
| imagenette2 | 0.969427 | 0.968662 | 0.970191 | 0.963312 | 0.963057 |
| MNIST | 0.9963 | 0.9969 | 0.9973 | 0.9964 | 0.997 |
| dogs-cats | 0.971831 | 0.99061 | 0.976526 | 0.971831 | 0.967136 |
| dogscats | 0.9855 | 0.9855 | 0.985 | 0.9875 | 0.9855 |
| cifar10 | 0.9589 | 0.9567 | 0.9571 | 0.954 | 0.9537 |
| PET | 0.919486 | 0.924899 | 0.907307 | 0.91475 | 0.897158 |
| insect | 0.8816 | 0.8832 | 0.8912 | 0.8808 | 0.868 |
ここで、6種類のデータセットのLearning rate finderでの結果を見てみます。
CIFAR10
MNIST
Oxford-IIIT-Pet
imagenette2
dogscats
dogs-cats
まとめ
●以外だったのは(と言うか知識不足か偶然か)
いづれのデータセットもLearning rate finderでのボトムは、ほぼ1e-3~1e-2のあたりにある。
●
最適な学習率はほぼ1e-5~1e-4あたり。
●もちろん1e-5~1e-4あたりで、3e-5にするとかpct_startを変えるとかの微調整をすれば、若干改善する余地がある。
まだまだ私の経験不足で今後どのように変化するか分かりませんが、今のところ学習率に関しては上記のような結論です。