前回・前々回とtransfer learningを行い、結果の分析まで進みました。
そのときConfusion matrixとかあまり説明をしていなかったので、まとめてここでしておきます。
fast.aiライブラリーを使って、fit()またはfit_one_cycle()でtarningした後、その結果を色々と分析できます。しかし、その度に時間を掛けてtrainingし直していたのでは時間の無駄です。
そこでtraining後に、
として、training結果を保存しておくと、次回からはそれを読み込んで作業を続けることが出来ます。
learn.save('learn-model')のlearnは、training時に作成したlearnerで、
learn = cnn_learner(data, models.resnet34, metrics=error_rate)の’=’の左側の名前です。
'learn-model'は保存する任意のファイル名で拡張子「.pth」のファイルが出来ます。
もう一つ、拡張子「.pkl」のファイルもありますが、それはまたpredictの時に・・・
保存したファイルを読み込むには、次のようにします。
Interpretation(学習結果の分析)
traningの結果を分析するのに、ClassificationInterpretationクラスを使用します。from_learnerメソッドを使って、次のように作成します。
Confusion matrix
confusion_matrixを使ってtrainingの全体像を俯瞰する事ができます。

縦軸のクラス名の画像を予測すると、横軸のクラス名の通りになったということです。
例えばairplaneの1000枚の画像を予測すると、960枚は正解のairplaneに、2枚はautomobile、4枚はbirdと判別されたということです。
Most confused categories
most_confusedは、最も頻繁に間違った予測と実際の特定の組み合わせを混同マトリックスから単純に取り出します。
min_valで間違った組み合わせの最小数を指定できます。
[('cat', 'dog', 69),
('dog', 'cat', 30),
('automobile', 'truck', 26),
('airplane', 'ship', 18),
('truck', 'automobile', 18),
('bird', 'frog', 16),
('ship', 'airplane', 15),
('deer', 'dog', 14),
('horse', 'dog', 13),
('bird', 'dog', 12),
('deer', 'horse', 12),
('ship', 'truck', 12),
('bird', 'airplane', 11),
('cat', 'deer', 11),
('frog', 'cat', 11),
('cat', 'frog', 10),
('deer', 'bird', 10),
('deer', 'cat', 10)]
Plot top losses
損失関数でみた損失上位の画像をplotすることが出来ます。
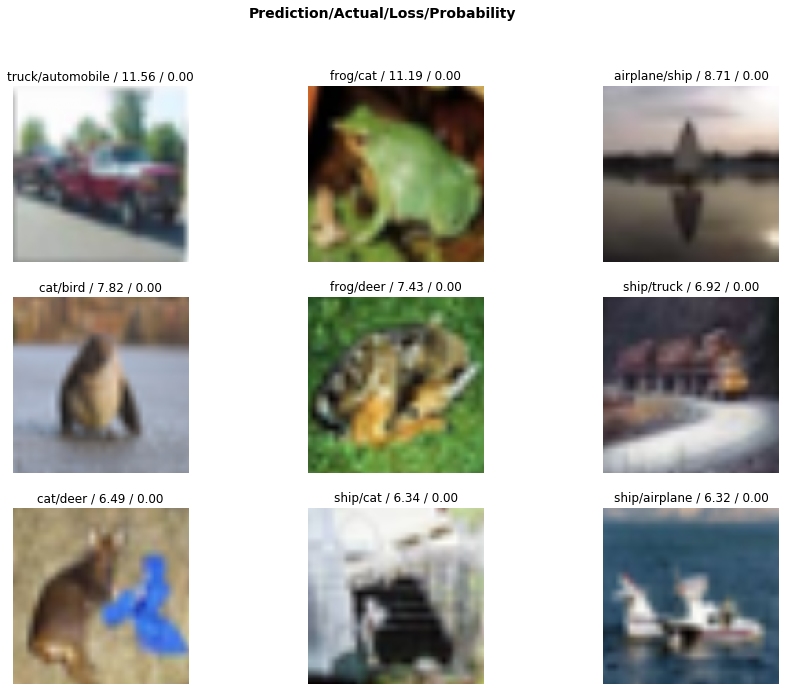
画像の上の4つの項目はそれぞれ、予測、実際、損失、実際のクラスの確率を示しています。
上段真ん中の「flog/cat/11.19/0.00」の画像は、cifar10の検証クラス(val)のcatクラスにある、ファイナル名236_catの画像です。カエルの画像が間違ってネコのクラスとして分類されてしまったのですネ。






