Transfer Learning Tutorial
Author: Sasank Chilamkurthy <https://chsasank.github.io>_In this tutorial, you will learn how to train your network using transfer learning. You can read more about the transfer learning at cs231n
notes <https://cs231n.github.io/transfer-learning/>__
PyTorchホームページのTutorialに手を加えて、いきなりTransfer Learningを試してみます。
Deep learningを基礎から勉強する人は、ゼロからモデルを作ったり(from scratch)もっと違う勉強が必要でしょうが、画像の分類のような何かをしたい人は、とにかくプログラムを動かす事が、興味を高める第一歩だと思います。
fast.aiの考え方もそうなんですかね。それからfast.aiを使うことでこのプログラムcodeが如何に楽になるか、私が体感したことを他の人にも知ってほしいと思います。
そのため同じようなプログラムを次回fast.aiを使って書いてみます。
(注意)
PyTorch.orgのホームページも結構更新されており、Tutorialにあるデモプログラムも変更されているので、このプログラムも削除されているかも知れません。
私は、機械学習用の資料を外付けHDDに入れて、UbuntuとWindows10で使っています。
またデータ類(cifar10、MNIST、Oxford-IIIT-Pet、ImageNetなど)は、まとめてDatasetフォルダーに入れています。
そこで、OSが替わってもデータを保存しているフォルダーを探しにいけるように、上のプログラムを追加しました。もっと良い方法があるのでしょうが取り敢えずこれで・・・。
またデータ類(cifar10、MNIST、Oxford-IIIT-Pet、ImageNetなど)は、まとめてDatasetフォルダーに入れています。
そこで、OSが替わってもデータを保存しているフォルダーを探しにいけるように、上のプログラムを追加しました。もっと良い方法があるのでしょうが取り敢えずこれで・・・。
ドライブ名は{DataScience}でWindowsでは「F:」ドライブとして認識するようにしています。
今回試すサンプルデータは、cifar10の生画像データで、私の場合は下記の様になっています。
(F:DataScience)
|
|---Dataset
|
|---cifar10
|
|---cifar10_png
|
|---train
| |
| |---airplane
| |---automobile
| |---bird
| ・・・
|---val
| |
| |---airplane
| |---automobile
| |---bird
| ・・・
Data augmentation and normalization for training
DataSetとDataLoader
Training the model
traning中に最もAccuracyの良かったモデルをpthファイルで、同じ階層の./modelに保存するようにしています。
従って事前に「./model」フォルダーを作成しておく必要があります。
学習済みモデルをFine-tuning (Finetuning the convnet)
Fine-tuningの選択
- model_select='total' --- すべての重みを更新する
- model_select='partial' --- 一部の重みのみを固定
model_select='total' では、重みを固定せずにResNet34の全レイヤの重みを更新対象としています。
しかし、Fine-tuningする場合は学習済みの重みを壊さないように固定した方がよいケースもある。
model_select='partial' では、最後の層を除くすべてのネットワークをフリーズする必要があります。 backward()で勾配が計算されないようにパラメータを固定するためにはrequire_grad == Falseを設定する必要があります。
- require_grad = False とすると重みを固定できる。更新対象から除く
こうすることで、最後の (fc)のLinear(512, class_num) のみをパラメータ更新の対象として残りのレイヤの重みはすべて固定することになる。
models.resnet34でモデルを読み込むとき、pretrained=Trueと設定すると、ImageNetで学習済の重みも取り込める。
ResNetの構造はあとで詳しく見てみる予定だけどとりあえず最後の (fc) に注目。
もともと出力がImageNetの1000クラス分類なので Linear(512, 1000) になっている。
この1000を目的とするクラス数に置き換える。
今回のcifar10では10クラスなので、Linear(512, 10) になる。
損失関数の定義
損失関数はnn.CrossEntropyLoss()を使用する。
活性化関数の定義
- optimizerには更新対象のパラメータのみ渡す必要がある ことに注意!従って、
- model_select == 'total'では、optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9)
- model_select == 'partial'では、optimizer_ft = optim.SGD(model_ft.fc.parameters(), lr=0.001, momentum=0.9)
- model_select='partial'でmodel.parameters() と固定したパラメータ含めて全部渡そうとするとエラーになる。
- backwardの勾配計算はネットワークの大部分で計算しなくて済むため前に比べて学習は早い(CPUでも動くレベル)。
- しかし、lossを計算するためforwardは計算しないといけない。
本当は、クラス毎のAccuracyや未知の画像のpredictなども書いているのですが、最小限に留めました。
実行の結果は
【model_select='partial' の場合】
Epoch 0/3
----------
train Loss: 1.3328 Acc: 0.5366
val Loss: 0.8412 Acc: 0.7126
Epoch 1/3
----------
train Loss: 1.2242 Acc: 0.5750
val Loss: 0.7916 Acc: 0.7264
Epoch 2/3
----------
train Loss: 1.1904 Acc: 0.5877
val Loss: 0.7457 Acc: 0.7448
Epoch 3/3
----------
train Loss: 1.1874 Acc: 0.5894
val Loss: 0.7143 Acc: 0.7606
Training complete in 10m 60s
Best val Acc: 0.760600


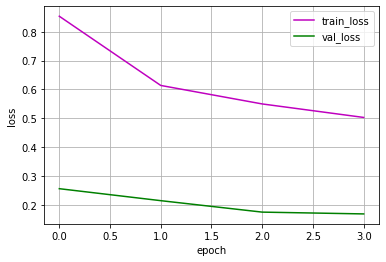
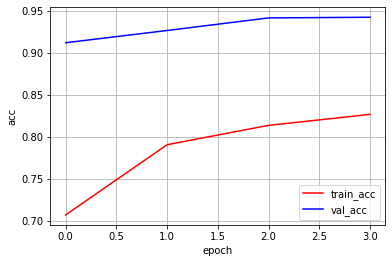
【model_select='total'の場合】
Epoch 0/3
----------
train Loss: 0.8535 Acc: 0.7068
val Loss: 0.2562 Acc: 0.9121
Epoch 1/3
----------
train Loss: 0.6138 Acc: 0.7905
val Loss: 0.2147 Acc: 0.9267
Epoch 2/3
----------
train Loss: 0.5497 Acc: 0.8136
val Loss: 0.1750 Acc: 0.9417
Epoch 3/3
----------
train Loss: 0.5030 Acc: 0.8267
val Loss: 0.1688 Acc: 0.9425
Training complete in 22m 53s
Best val Acc: 0.942500
0 件のコメント:
コメントを投稿